
Snowflake内のテーブルデータに対して自然言語で問い合わせを行う仕組みを簡単に構築できる「Cortex Analyst」を試してみた
この記事は公開されてから1年以上経過しています。情報が古い可能性がありますので、ご注意ください。
さがらです。
Snowflake内のテーブルデータに対して自然言語で問い合わせを行う仕組みを簡単に構築できる「Cortex Analyst」がAWSのUSやEUのリージョンでパブリックプレビューとなりました!(日本などのリージョンでも、Cross-region inferenceという機能を使えば利用できるようです。)
ドキュメントも併せて公開されています。
個人的に待望していた機能なので「とりあえず触ってみたい!」という思いから、下記のチュートリアルを試してみたので、本記事でその内容をまとめてみます。
参考:Cortex Analystのコストについて
こういったLLM関係の機能だと気になるコストですが、公式Docには下記のように書いてありました!2024年9月15日までは無料のため、がんがん使っていきましょう!
Cortex Analyst is free until September 15, 2024. Details on pricing and billing will be available soon.」
検証環境
- Snowflake
- Enterpriseエディション
- US West(Oregon)リージョン
サンプルデータ・プログラムの取得
まず下記のGoogleドライブから、すべてのファイルをダウンロードします。
後でSnowflakeにロードするのは下記3つのファイルとなります。
daily_revenue_combined.csvdaily_revenue_by_region_combined.csvdaily_revenue_by_product_combined.csv
また、Semantic Modelを定義しているrevenue_timeseries.yamlの内容も確認してみます。
基本的にはテーブル1つごとに、dimensionやmeasureを定めていく、他のSemantic Layerの製品と同じような仕様となっていますね。
個人的には、synonymsというパラメータで同義語を定義できるのは嬉しいですね!様々な用語で問い合わせを受けることが多いと思うので、synonymsでリストとして定義できるのは良い点だと思います。
name: Revenue
tables:
- name: daily_revenue
description: Daily total revenue, aligned with daily "Cost of Goods Sold" (COGS), and forecasted revenue.
base_table:
database: cortex_analyst_demo
schema: revenue_timeseries
table: daily_revenue
time_dimensions:
- name: date
expr: date
description: date with measures of revenue, COGS, and forecasted revenue.
unique: true
data_type: date
measures:
- name: daily_revenue
expr: revenue
description: total revenue for the given day
synonyms: ["sales", "income"]
default_aggregation: sum
data_type: number
- name: daily_cogs
expr: cogs
description: total cost of goods sold for the given day
synonyms: ["cost", "expenditures"]
default_aggregation: sum
data_type: number
- name: daily_forecasted_revenue
expr: forecasted_revenue
description: total forecasted revenue for a given day
synonyms: ["forecasted sales", "forecasted income"]
default_aggregation: sum
data_type: number
- name: daily_profit
description: profit is the difference between revenue and expenses.
expr: revenue - cogs
data_type: number
- name: daily_forecast_abs_error
synonyms:
- absolute error
- L1
description: absolute error between forecasted and actual revenue
expr: abs(forecasted_revenue - revenue)
data_type: number
default_aggregation: avg
- name: daily_revenue_by_product_line
description: Daily revenue sliced by product line, aligned with daily "Cost of Goods Sold" (COGS), and forecasted revenue.
base_table:
database: cortex_analyst_demo
schema: revenue_timeseries
table: daily_revenue_by_product
time_dimensions:
- name: date
expr: date
description: date with measures of revenue, COGS, and forecasted revenue for each product line
unique: false
data_type: date
dimensions:
- name: product_line
expr: product_line
description: product line associated with it's own slice of revenue
unique: false
data_type: varchar
sample_values:
- Electronics
- Clothing
- Home Appliances
- Toys
- Books
measures:
- name: daily_revenue_per_product_line
expr: revenue
description: revenue associated with a given product line for the given day
synonyms: ["sales", "income"]
default_aggregation: sum
data_type: number
- name: daily_cogs_per_product_line
expr: cogs
description: cost of goods sold associated with a given product line for the given day
synonyms: ["cost", "expenditures"]
default_aggregation: sum
data_type: number
- name: daily_forecasted_revenue_per_product_line
expr: forecasted_revenue
description: total forecasted revenue associated with a given product line for the given day
synonyms: ["forecasted sales", "forecasted income"]
default_aggregation: sum
data_type: number
- name: daily_profit_per_product_line
description: profit is the difference between revenue and expenses.
expr: revenue - cogs
data_type: number
- name: daily_forecast_abs_error_per_product_line
synonyms:
- absolute error
- L1
description: absolute error between forecasted and actual revenue
expr: abs(forecasted_revenue - revenue)
data_type: number
default_aggregation: avg
- name: daily_revenue_by_region
description: Daily revenue sliced by region, aligned with daily "Cost of Goods Sold" (COGS), and forecasted revenue.
base_table:
database: cortex_analyst_demo
schema: revenue_timeseries
table: daily_revenue_by_region
time_dimensions:
- name: date
expr: date
description: date with measures of revenue, COGS, and forecasted revenue for each region
unique: false
data_type: date
dimensions:
- name: sales_region
expr: sales_region
description: region associated with it's own slice of revenue
unique: false
data_type: varchar
sample_values:
- North America
- Europe
- Asia
- South America
- Africa
measures:
- name: daily_revenue_per_sales_region
expr: revenue
description: revenue associated with a given region for the given day
synonyms: ["sales", "income"]
default_aggregation: sum
data_type: number
- name: daily_cogs_per_sales_region
expr: cogs
description: cost of goods sold associated with a given region for the given day
synonyms: ["cost", "expenditures"]
default_aggregation: sum
data_type: number
- name: daily_forecasted_revenue_per_sales_region
expr: forecasted_revenue
description: total forecasted revenue associated with a given region for the given day
synonyms: ["forecasted sales", "forecasted income"]
default_aggregation: sum
data_type: number
- name: daily_profit_per_sales_region
description: profit is the difference between revenue and expenses.
expr: revenue - cogs
data_type: number
- name: daily_forecast_abs_error_per_sales_region
synonyms:
- absolute error
- L1
description: absolute error between forecasted and actual revenue
expr: abs(forecasted_revenue - revenue)
data_type: number
default_aggregation: avg
verified_queries:
# For eval sample nlimtiaco_sc_3__0
- name: "daily cumulative expenses in 2023 dec"
question: "daily cumulative expenses in 2023 dec"
verified_at: 1714752498
verified_by: renee
sql: "
SELECT
date,
SUM(daily_cogs) OVER (
ORDER BY
date ROWS BETWEEN UNBOUNDED PRECEDING
AND CURRENT ROW
) AS cumulative_cogs
FROM
__daily_revenue
WHERE
date BETWEEN '2023-12-01'
AND '2023-12-31'
ORDER BY
date DESC;
"
# For eval sample nlimtiaco_sc_6__0
- name: "lowest revenue each month"
question: For each month, what was the lowest daily revenue and on what date did
that lowest revenue occur?
sql: "WITH monthly_min_revenue AS (
SELECT
DATE_TRUNC('MONTH', date) AS month,
MIN(daily_revenue) AS min_revenue
FROM __daily_revenue
GROUP BY
DATE_TRUNC('MONTH', date)
)
SELECT
mmr.month,
mmr.min_revenue,
dr.date AS min_revenue_date
FROM monthly_min_revenue AS mmr JOIN __daily_revenue AS dr
ON mmr.month = DATE_TRUNC('MONTH', dr.date) AND mmr.min_revenue = dr.daily_revenue
ORDER BY mmr.month DESC NULLS LAST"
verified_at: 1715187400
verified_by: renee
Snowflakeでのオブジェクトの作成
以下のクエリをSnowsightのワークシートで実行して、チュートリアルに必要なデータベース・スキーマ・テーブル・ステージ・ウェアハウスを作成します。
/*--
• database, schema, warehouse and stage creation
--*/
-- create demo database
CREATE OR REPLACE DATABASE cortex_analyst_demo;
-- create schema
CREATE OR REPLACE SCHEMA revenue_timeseries;
-- create warehouse
CREATE OR REPLACE WAREHOUSE cortex_analyst_wh
WAREHOUSE_SIZE = 'large'
WAREHOUSE_TYPE = 'standard'
AUTO_SUSPEND = 60
AUTO_RESUME = TRUE
INITIALLY_SUSPENDED = TRUE
COMMENT = 'warehouse for cortex analyst demo';
USE WAREHOUSE cortex_analyst_wh;
CREATE STAGE raw_data DIRECTORY = (ENABLE = TRUE);
/*--
• table creation
--*/
CREATE OR REPLACE TABLE CORTEX_ANALYST_DEMO.REVENUE_TIMESERIES.DAILY_REVENUE (
DATE DATE,
REVENUE FLOAT,
COGS FLOAT,
FORECASTED_REVENUE FLOAT
);
CREATE OR REPLACE TABLE CORTEX_ANALYST_DEMO.REVENUE_TIMESERIES.DAILY_REVENUE_BY_PRODUCT (
DATE DATE,
PRODUCT_LINE VARCHAR(16777216),
REVENUE FLOAT,
COGS FLOAT,
FORECASTED_REVENUE FLOAT
);
CREATE OR REPLACE TABLE CORTEX_ANALYST_DEMO.REVENUE_TIMESERIES.DAILY_REVENUE_BY_REGION (
DATE DATE,
SALES_REGION VARCHAR(16777216),
REVENUE FLOAT,
COGS FLOAT,
FORECASTED_REVENUE FLOAT
);
Snowflakeへのデータロード
次に、ダウンロードしたCSVとYAMLの合計4種類のファイルを、Snowsightでステージにアップロードします。先程作成したデータベース・スキーマ・ステージを選択する点だけ注意しましょう。
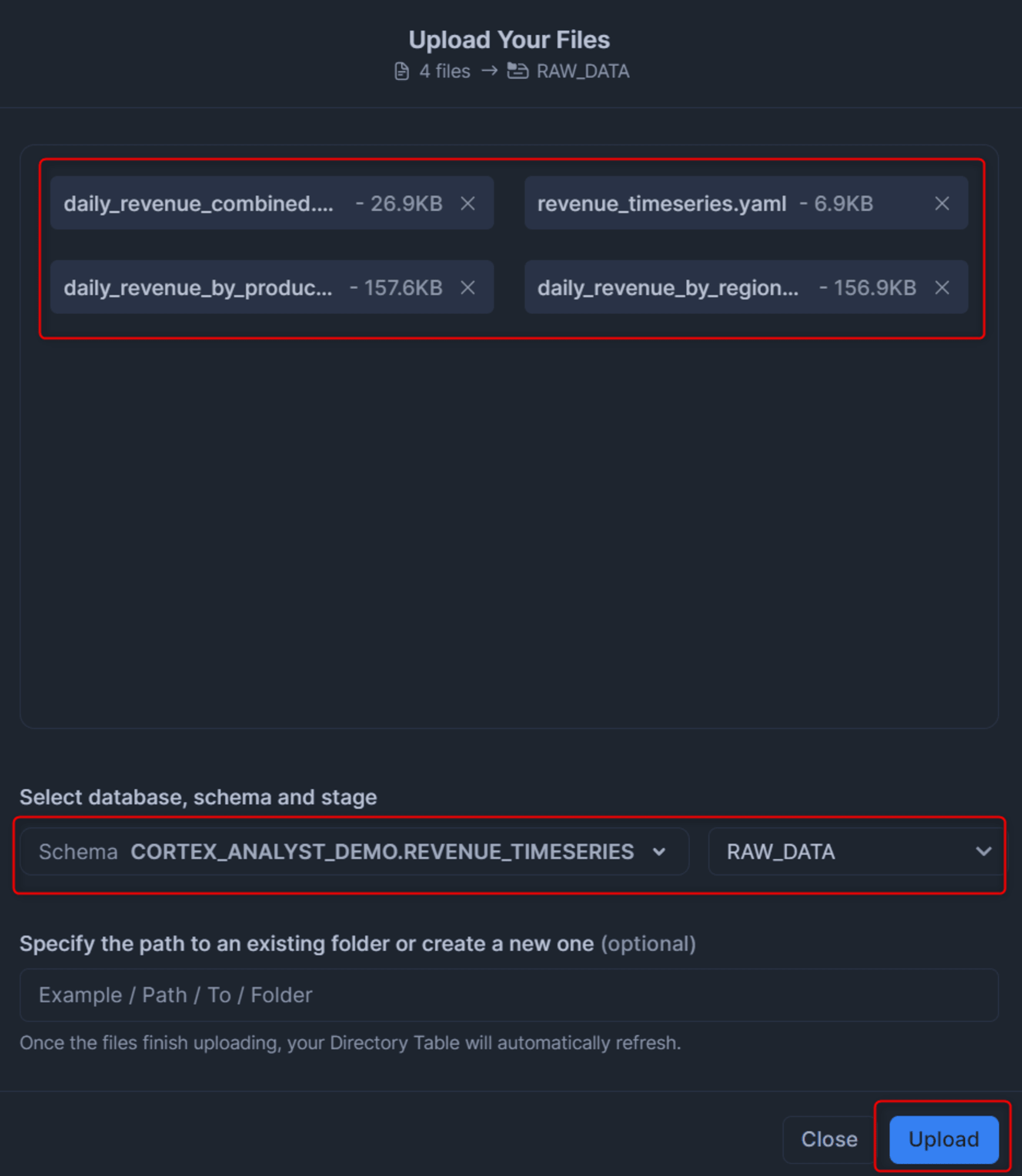
次に、以下のクエリを実行して各テーブルにデータをロードします。
COPY INTO CORTEX_ANALYST_DEMO.REVENUE_TIMESERIES.DAILY_REVENUE
FROM @raw_data
FILES = ('daily_revenue_combined.csv')
FILE_FORMAT = (
TYPE=CSV,
SKIP_HEADER=1,
FIELD_DELIMITER=',',
TRIM_SPACE=FALSE,
FIELD_OPTIONALLY_ENCLOSED_BY=NONE,
REPLACE_INVALID_CHARACTERS=TRUE,
DATE_FORMAT=AUTO,
TIME_FORMAT=AUTO,
TIMESTAMP_FORMAT=AUTO
EMPTY_FIELD_AS_NULL = FALSE
error_on_column_count_mismatch=false
)
ON_ERROR=CONTINUE
FORCE = TRUE ;
COPY INTO CORTEX_ANALYST_DEMO.REVENUE_TIMESERIES.DAILY_REVENUE_BY_PRODUCT
FROM @raw_data
FILES = ('daily_revenue_by_product_combined.csv')
FILE_FORMAT = (
TYPE=CSV,
SKIP_HEADER=1,
FIELD_DELIMITER=',',
TRIM_SPACE=FALSE,
FIELD_OPTIONALLY_ENCLOSED_BY=NONE,
REPLACE_INVALID_CHARACTERS=TRUE,
DATE_FORMAT=AUTO,
TIME_FORMAT=AUTO,
TIMESTAMP_FORMAT=AUTO
EMPTY_FIELD_AS_NULL = FALSE
error_on_column_count_mismatch=false
)
ON_ERROR=CONTINUE
FORCE = TRUE ;
COPY INTO CORTEX_ANALYST_DEMO.REVENUE_TIMESERIES.DAILY_REVENUE_BY_REGION
FROM @raw_data
FILES = ('daily_revenue_by_region_combined.csv')
FILE_FORMAT = (
TYPE=CSV,
SKIP_HEADER=1,
FIELD_DELIMITER=',',
TRIM_SPACE=FALSE,
FIELD_OPTIONALLY_ENCLOSED_BY=NONE,
REPLACE_INVALID_CHARACTERS=TRUE,
DATE_FORMAT=AUTO,
TIME_FORMAT=AUTO,
TIMESTAMP_FORMAT=AUTO
EMPTY_FIELD_AS_NULL = FALSE
error_on_column_count_mismatch=false
)
ON_ERROR=CONTINUE
FORCE = TRUE ;
Streamlitアプリの構築
※チュートリアルではローカルのPythonを使用してCortex Analystを用いたチャットボットを構築していますが、GoogleドライブにStreamlit in Snowflakeでそのまま動かすことができるPythonコードがあるため、それを使用します。
次に、Streamlitのアプリを作成します。先程作成したデータベース・スキーマ・ウェアハウスを選択して作成します。
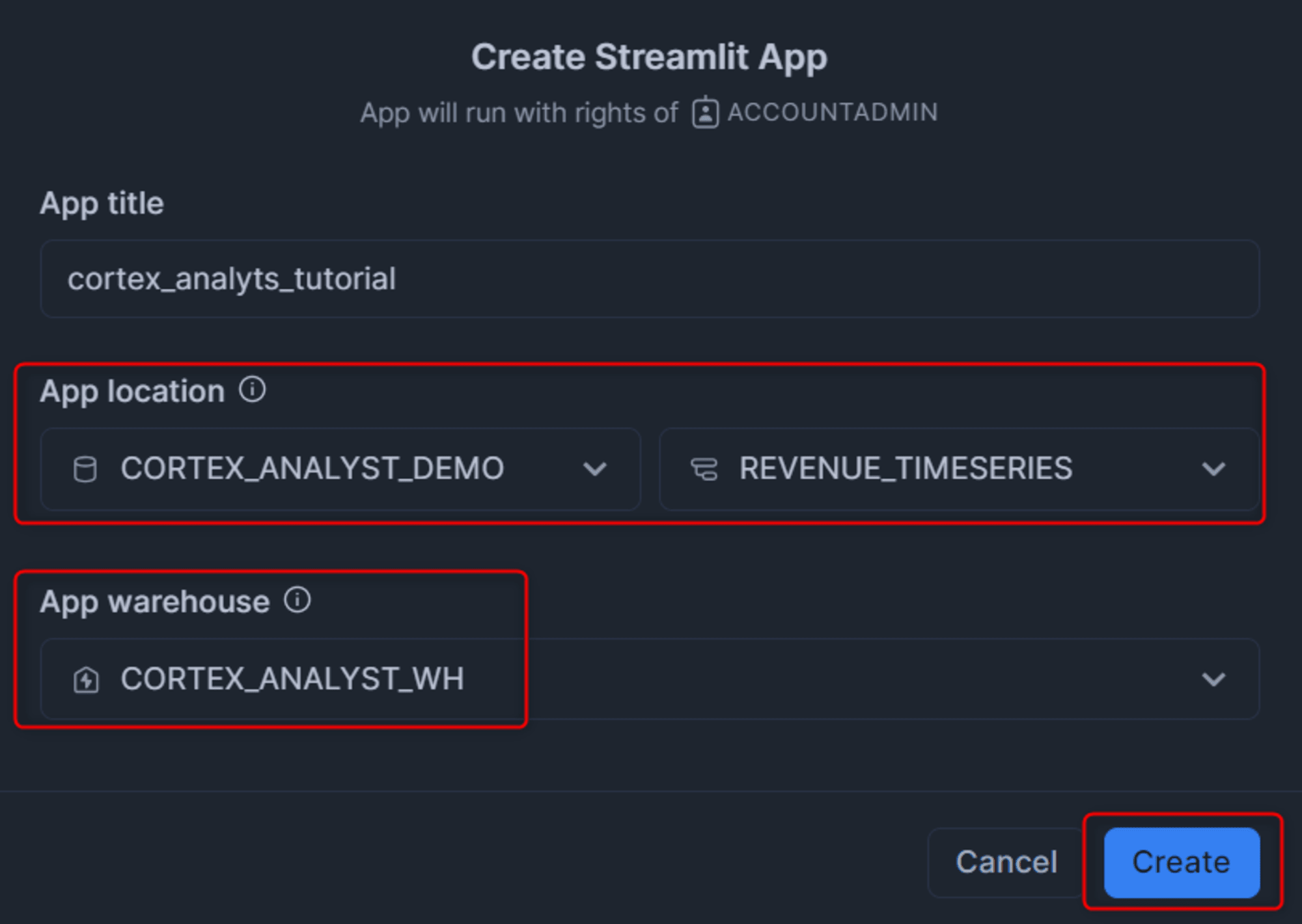
作成したら、先程Googleドライブからダウンロードしたcortex_analyst_sis_demo_app.pyの内容をそのままコピーします。(下記は私がダウンロードしたときの本ファイルのコードです。)
注目すべきはdef send_message(prompt: str) -> dict:の関数で、ここではCortex AnalystのAPIであるPOST /api/v2/cortex/analyst/messageを使用しています。Cortex Analystとしては使用するテーブルとSemantic Modelを決めたらこのAPIを叩くだけなので、非常に簡単に使えることがわかります。
このAPIの仕様については下記のドキュメントをご覧ください。
import _snowflake
import json
import streamlit as st
import time
from snowflake.snowpark.context import get_active_session
DATABASE = "CORTEX_ANALYST_DEMO"
SCHEMA = "REVENUE_TIMESERIES"
STAGE = "RAW_DATA"
FILE = "revenue_timeseries.yaml"
def send_message(prompt: str) -> dict:
"""Calls the REST API and returns the response."""
request_body = {
"messages": [
{
"role": "user",
"content": [
{
"type": "text",
"text": prompt
}
]
}
],
"semantic_model_file": f"@{DATABASE}.{SCHEMA}.{STAGE}/{FILE}",
}
resp = _snowflake.send_snow_api_request(
"POST",
f"/api/v2/cortex/analyst/message",
{},
{},
request_body,
{},
30000,
)
if resp["status"] < 400:
return json.loads(resp["content"])
else:
raise Exception(
f"Failed request with status {resp['status']}: {resp}"
)
def process_message(prompt: str) -> None:
"""Processes a message and adds the response to the chat."""
st.session_state.messages.append(
{"role": "user", "content": [{"type": "text", "text": prompt}]}
)
with st.chat_message("user"):
st.markdown(prompt)
with st.chat_message("assistant"):
with st.spinner("Generating response..."):
response = send_message(prompt=prompt)
content = response["message"]["content"]
display_content(content=content)
st.session_state.messages.append({"role": "assistant", "content": content})
def display_content(content: list, message_index: int = None) -> None:
"""Displays a content item for a message."""
message_index = message_index or len(st.session_state.messages)
for item in content:
if item["type"] == "text":
st.markdown(item["text"])
elif item["type"] == "suggestions":
with st.expander("Suggestions", expanded=True):
for suggestion_index, suggestion in enumerate(item["suggestions"]):
if st.button(suggestion, key=f"{message_index}_{suggestion_index}"):
st.session_state.active_suggestion = suggestion
elif item["type"] == "sql":
with st.expander("SQL Query", expanded=False):
st.code(item["statement"], language="sql")
with st.expander("Results", expanded=True):
with st.spinner("Running SQL..."):
session = get_active_session()
df = session.sql(item["statement"]).to_pandas()
if len(df.index) > 1:
data_tab, line_tab, bar_tab = st.tabs(
["Data", "Line Chart", "Bar Chart"]
)
data_tab.dataframe(df)
if len(df.columns) > 1:
df = df.set_index(df.columns[0])
with line_tab:
st.line_chart(df)
with bar_tab:
st.bar_chart(df)
else:
st.dataframe(df)
st.title("Cortex analyst")
st.markdown(f"Semantic Model: `{FILE}`")
if "messages" not in st.session_state:
st.session_state.messages = []
st.session_state.suggestions = []
st.session_state.active_suggestion = None
for message_index, message in enumerate(st.session_state.messages):
with st.chat_message(message["role"]):
display_content(content=message["content"], message_index=message_index)
if user_input := st.chat_input("What is your question?"):
process_message(prompt=user_input)
if st.session_state.active_suggestion:
process_message(prompt=st.session_state.active_suggestion)
st.session_state.active_suggestion = None
すると、下図のようにチャットボットが構築されます。
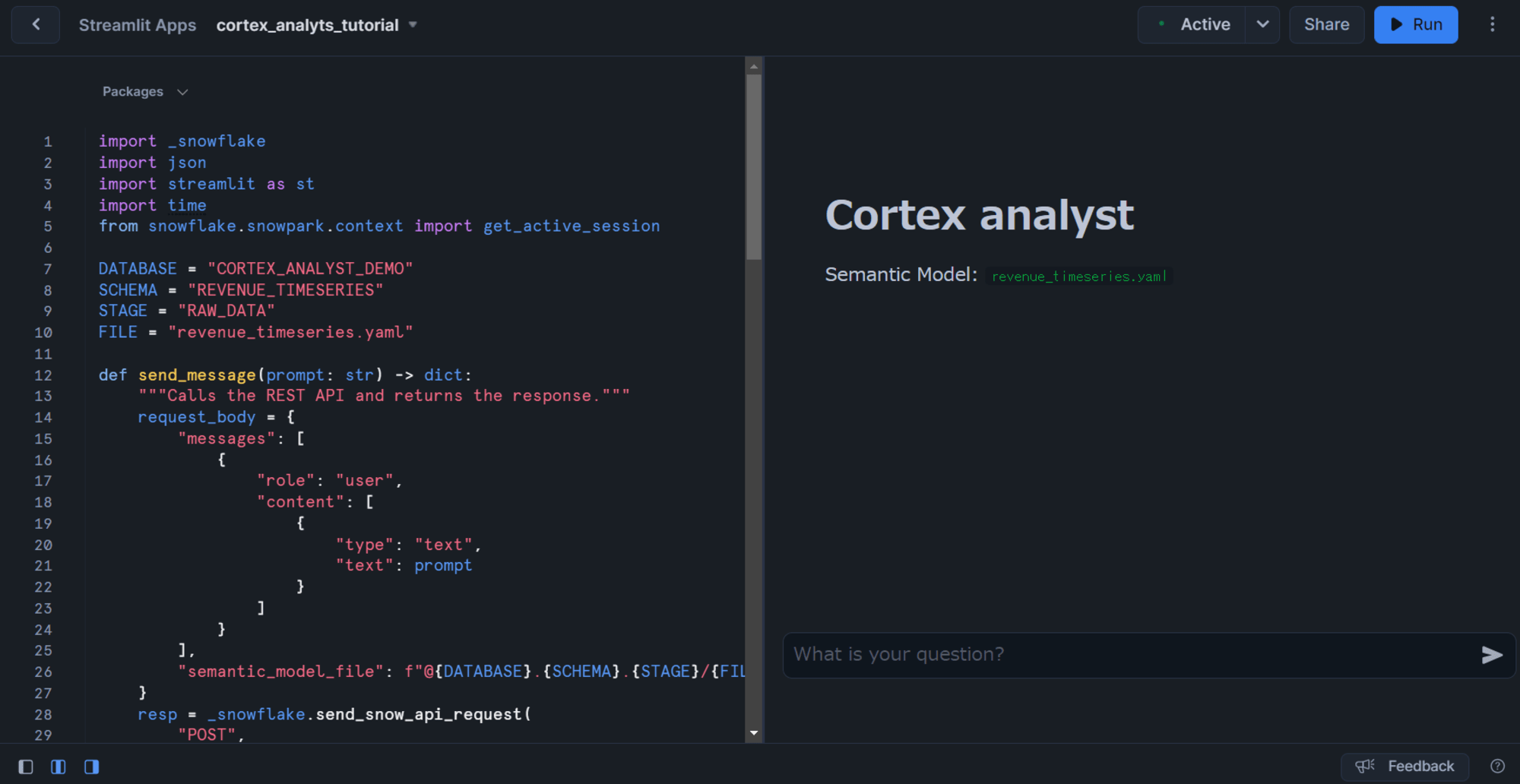
実際に質問してみた
雑に日本語で質問
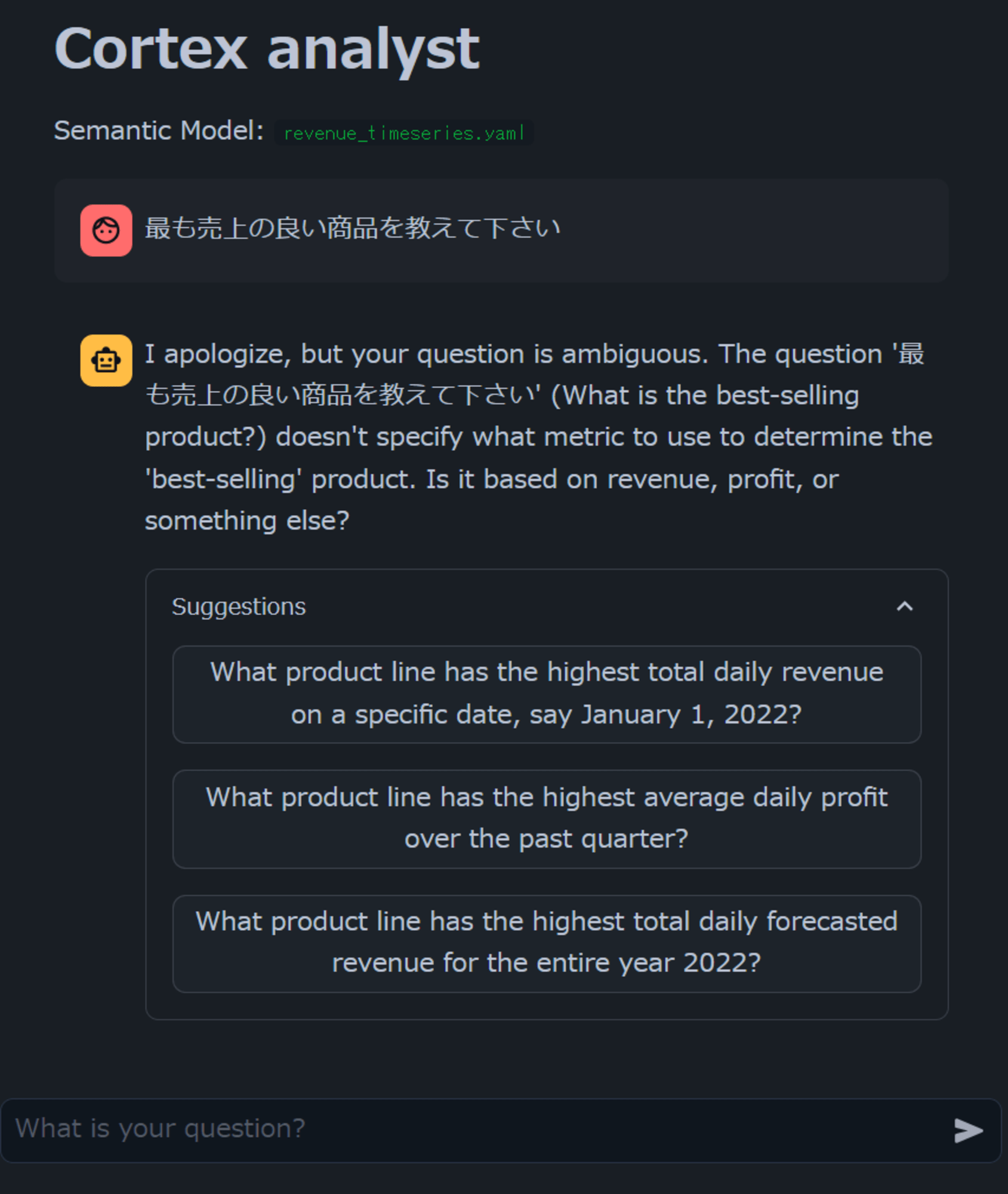
まず、雑に日本語で最も売上の良い商品を教えて下さいと聞いてみました。すると日本語の内容を英語に翻訳した上で、「revenue、profit、それ以外、どれに関するbest-sellingを知りたいのか」候補を出してくれました。
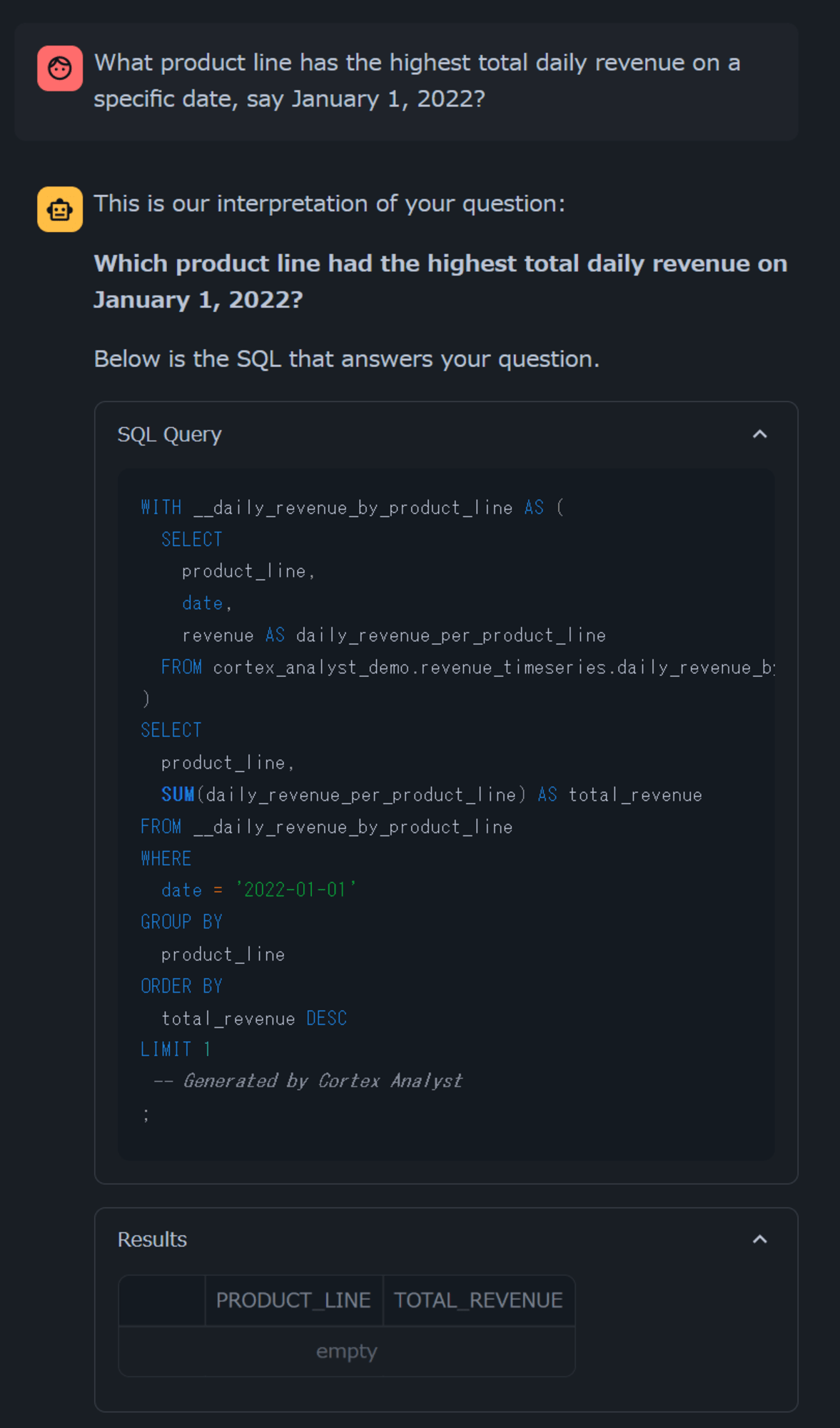
試しに、一番上のWhat product line has the highest total daily revenue on a specific date, say January 1, 2022?をクリックしてみると、質問の答えを返すためのクエリとデータを返してくれました。(データがEmptyですが…)
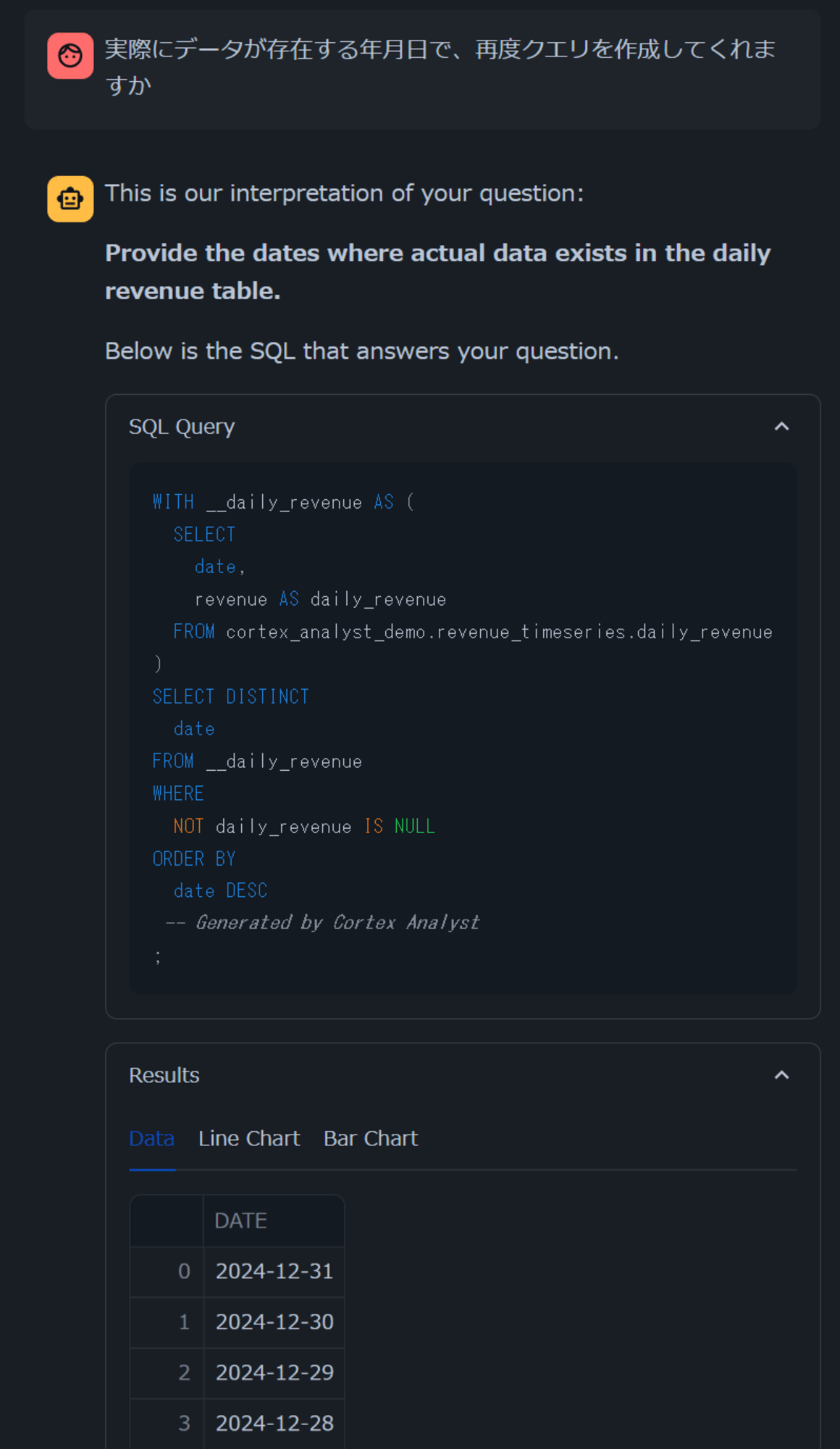
先ほどのクエリだとデータが存在しなかったため、「実際にデータが存在する年月日で、再度クエリを作成してくれますか」と聞いてみると、実際にデータが存在する年月日を返すクエリを作成してくれました。(問い合わせ文の問題も大いにありますが、一つ前の問い合わせの内容を書き換えてくれなかったのは惜しい点ですね。)
Semantic Modelで定義されているMeasureについて質問
次に、少し経路を変えて、このSemantic Modelで登録されているMeasureについて質問をしてみたいと思います。具体的には、「forecasted_revenue」について聞いてみます。
Semantic Modelのyamlでは、下記のように定義がされています。
- name: daily_forecasted_revenue_per_product_line
expr: forecasted_revenue
description: total forecasted revenue associated with a given product line for the given day
synonyms: ["forecasted sales", "forecasted income"]
default_aggregation: sum
data_type: number
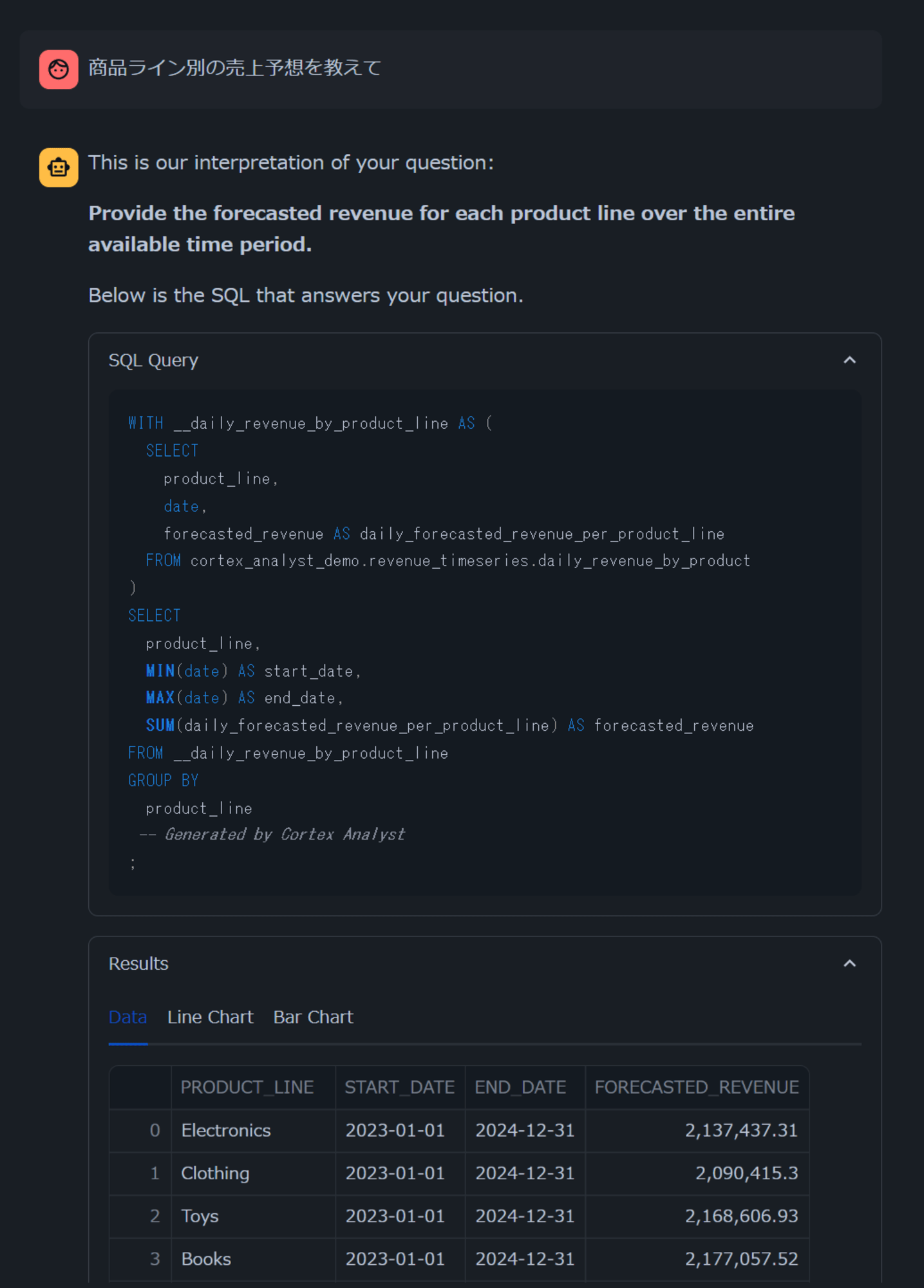
まず、日本語で訳した内容で「商品ライン別の売上予想を教えて」と聞いてみます。
すると、「Provide the forecasted revenue for each product line over the entire available time period.」と翻訳されたうえで、意図した結果が返ってきました!英語でSemantic Modelが定義されていても、日本語の翻訳結果が合致すれば正しい結果が返ってきそうです。
最後に
簡単ではありますが、Snowflake内のテーブルデータに対して自然言語で問い合わせを行う仕組みを簡単に構築できる「Cortex Analyst」がAWSのUSやEUのリージョンでパブリックプレビューとなったので、そのチュートリアルを試してみました。
テーブルとSemantic Modelを定義したらCortex AnalystのAPIを使うだけで、問い合わせに対応する結果を得るためのクエリを自動で生成してくれるため、非常に楽ですね!
今回はチュートリアルのデータがすべて英語でしたが、日本語で問い合わせても翻訳結果が合致すれば適切な回答を返してくれるのも嬉しい点でした。
2024年9月15日まで無料で使用できるので、ぜひ触ってみてください!







